
Analyzing Tennis Matches with Machine Learning – The Evolution of Tennis Data
Fans have tracked rankings, match results, tournament records, and player statistics for decades. However, in recent years, the way tennis data is collected, analyzed, and utilized has changed dramatically. What was once primarily used by journalists and commentators is now powering sophisticated machine learning models, betting algorithms, coaching tools, and predictive analytics platforms. This evolution has made Tennis Data Analytics an essential field for understanding player performance, predicting match outcomes, and uncovering valuable insights from large datasets.
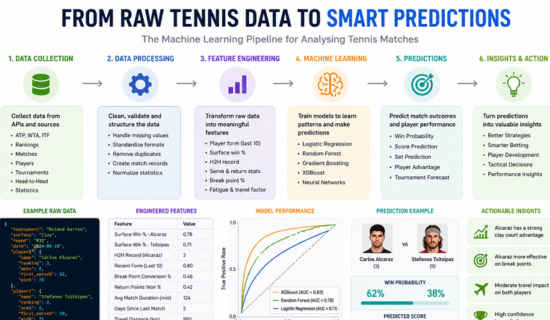
The combination of increasingly comprehensive datasets and advances in machine learning has transformed how we understand tennis performance. Today, analysts can process millions of historical data points to identify patterns that would be impossible to detect manually.
As tennis data continues to evolve, machine learning is becoming one of the most powerful tools available to researchers, developers, and sports analysts.
Tennis has always been a sport of numbers.
The Early Days of Tennis Data
Historically, tennis statistics were relatively simple. Match results, tournament winners, rankings, and win-loss records formed the foundation of most analysis.
While these statistics were useful, they often provided only a surface-level understanding of player performance.
Questions such as:
- How does a player perform against aggressive baseliners?
- Does altitude affect performance?
- How much does travel impact results?
- Which surfaces create the largest performance differences?
were difficult to answer because the underlying datasets were limited.
As professional tennis expanded and data collection improved, analysts gained access to richer information. Match statistics, point-level data, serve percentages, return effectiveness, break point conversion rates, and countless other metrics became available.
This opened the door for more advanced analytical approaches.
Tennis Data Analytics in Machine Learning
Machine learning differs from traditional statistical analysis because it focuses on discovering patterns automatically rather than relying solely on predefined assumptions.
Instead of manually determining which factors matter most, machine learning algorithms can evaluate thousands of variables simultaneously and identify relationships hidden within large datasets.
In tennis, machine learning models are increasingly used for:
- Match prediction
- Player performance forecasting
- Ranking projections
- Injury risk analysis
- Tournament simulations
- Betting market analysis
- Player development programs
Professional teams, analysts, betting companies, and independent researchers are all exploring ways to gain insights from tennis data using machine learning techniques.
Why Tennis Is Ideal for Machine Learning
Tennis offers several characteristics that make it particularly suitable for predictive modelling.
Unlike many team sports, tennis matches are primarily influenced by two competitors. This significantly reduces complexity when compared with sports such as football or cricket, where numerous players interact simultaneously.
Tennis also generates large quantities of structured data.
For every match, analysts may have access to:
- Player rankings
- Surface type
- Tournament category
- Historical head-to-head records
- Recent form
- Serve statistics
- Return statistics
- Match duration
- Travel schedules
- Age and experience factors
This abundance of structured information creates an ideal environment for machine learning algorithms.
Feature Engineering: The Real Secret
One common misconception is that machine learning success depends entirely on choosing the right algorithm.
In reality, the quality of the input data often matters far more.
Feature engineering—the process of transforming raw data into useful predictive variables—is often the most important part of any tennis machine learning project.
Examples of useful tennis features include:
- Win percentage over the last 10 matches
- Surface-specific win rate
- Head-to-head record
- Recent injury history
- Performance against top-20 opponents
- Break point conversion percentage
- Tournament-specific history
- Travel distance between events
Machine learning models become significantly more powerful when fed high-quality, context-rich features.
The Importance of Historical Tennis Data
The foundation of every successful Tennis Data Analytics prediction model is historical data.
Without large historical datasets, machine learning algorithms cannot learn meaningful patterns.
The best models often use years—or even decades—of historical match records to train predictive systems.
Historical data allows models to identify:
- Long-term performance trends
- Surface preferences
- Ranking progression
- Player development patterns
- Tournament-specific performance
- Matchup tendencies
As a result, access to deep historical databases has become increasingly valuable for researchers and developers working on tennis analytics projects.
Modern Tennis Data Requirements
Building modern machine learning systems requires significantly more data than traditional sports analysis.
Today, developers often need comprehensive datasets that include:
- ATP matches
- WTA matches
- Challenger Tour events
- ITF tournaments
- Rankings history
- Tournament information
- Player profiles
- Head-to-head records
- Surface statistics
- Match-level statistics
The broader the dataset, the greater the opportunities for discovering meaningful patterns.
For this reason, many machine learning practitioners seek APIs and data providers that offer extensive historical coverage rather than focusing solely on live scores.
The Role of APIs in Tennis Analytics
In the past, collecting tennis data often involved scraping websites or manually building databases.
Today, APIs have largely solved this problem.
Developers can access structured tennis data through dedicated tennis data providers, dramatically reducing the time required to build analytics systems.
For example, detailed coverage information for professional tennis competitions can be found through resources such as this tennis API coverage page, which outlines the breadth of ATP, WTA, Challenger, and ITF data available to developers.
Comprehensive API coverage is particularly important because machine learning projects often require large volumes of historical information rather than simply current rankings or live scores.
Getting Started with Tennis Data APIs
For developers entering the tennis analytics space, APIs provide the fastest path to acquiring structured data.
Rather than spending months collecting and organizing datasets, developers can focus on feature engineering, model development, and application design.
Resources such as the Tennis API tutorials available through RapidAPI help developers understand how to retrieve rankings, match results, player information, historical records, and other data needed for analytical applications.
This accessibility has significantly lowered the barrier to entry for tennis machine learning projects.
Current Challenges in Tennis Machine Learning
Despite the abundance of available data, tennis prediction remains challenging.
Human performance is inherently unpredictable.
Factors such as:
- Injuries
- Fatigue
- Weather conditions
- Psychological factors
- Motivation levels
- Travel schedules
can dramatically influence outcomes.
Even the most advanced models cannot perfectly account for every variable.
As a result, machine learning should be viewed as a tool for improving decision-making rather than eliminating uncertainty.
The Future of Tennis Analytics
The future of Tennis Data Analytics will likely be driven by even richer datasets and more sophisticated machine learning techniques.
Emerging technologies such as computer vision, player tracking systems, biomechanical analysis, and real-time data processing are creating entirely new categories of information.
Future models may incorporate:
- Player movement tracking
- Shot placement analysis
- Ball trajectory data
- Fatigue estimation
- Biomechanical measurements
- Real-time match adjustments
As these technologies mature, the predictive power of tennis analytics is likely to improve substantially.
Conclusion
The evolution of Tennis Data Analytics has transformed the sport from a statistics-rich environment into a machine learning playground.
What began with simple rankings and match results has expanded into vast databases containing millions of historical records and performance indicators.
Machine learning has enabled analysts to extract meaningful insights from this information, supporting applications ranging from match prediction and betting models to coaching tools and player development systems.
However, successful machine learning projects still depend on one critical ingredient: high-quality data.
As tennis APIs continue to expand their coverage and historical depth, developers and researchers will gain even greater opportunities to explore, analyse, and predict the sport using advanced analytical techniques.












Post Comment
You must be logged in to post a comment.