
Unsupervised Learning in AI: A Clear & Easy Guide
Introduction
Unsupervised Learning is becoming increasingly important as businesses collect huge amounts of information from websites, mobile apps, social media platforms, sensors, and customer interactions every day. However, much of this data does not come with labels or categories. As a result, finding useful insights can be difficult.
Fortunately, this is where Unsupervised Learning becomes valuable. Unlike traditional approaches that rely on labeled data, it helps computers discover patterns, relationships, and structures without being given predefined answers. Instead, the algorithm explores the data independently and identifies meaningful connections.
Moreover, companies across many industries use unsupervised learning to better understand customers, improve services, detect unusual activity, and make smarter decisions. Therefore, learning how this technology works is becoming increasingly important for anyone interested in machine learning, data science, or artificial intelligence.
What Is Unsupervised Learning?
Simply put, Unsupervised Learning is a machine learning approach that works with unlabeled datasets. In other words, the data does not contain predefined categories, labels, or outcomes.
Instead of predicting answers, the algorithm searches for similarities, differences, and hidden patterns within the data. As a result, it can organize information into meaningful groups and reveal relationships that may not be obvious at first glance.
For example, imagine a company has thousands of customer records but does not know which customers share similar behaviors. In this situation, an unsupervised learning model can analyze purchasing habits and automatically create useful customer segments. Consequently, the company can better understand its audience and improve its marketing efforts.
Read More: Unsupervised Learning Method: You Need to Know

Unsupervised Learning vs. Supervised Learning
Although both approaches are important branches of machine learning, they serve different purposes.
| Feature | Supervised Learning | Unsupervised Learning |
|---|---|---|
| Data Type | Labeled Data | Unlabeled Data |
| Main Goal | Predict Outcomes | Discover Patterns |
| Human Guidance | Required | Minimal |
| Common Tasks | Classification, Regression | Clustering, Association |
| Output | Predictions | Groups and Relationships |
| Evaluation | Easier | More Subjective |
In simple terms, supervised learning answers specific questions based on known examples. In contrast, unsupervised learning explores data to uncover new insights and hidden relationships. Therefore, it is especially useful when organizations do not know exactly what patterns they are looking for.
Why Unsupervised Learning Matters?
Today, organizations generate more data than ever before. However, manually labeling every record can be expensive, time-consuming, and sometimes impossible.
Therefore, unsupervised learning provides an efficient way to analyze information without requiring extensive human effort. As a result, businesses can gain valuable insights much faster.
Read More: Unsupervised learning
Finding Hidden Patterns
One of the biggest advantages of unsupervised learning is its ability to uncover hidden patterns that may otherwise go unnoticed.
For instance, a retailer may discover that certain groups of customers have similar buying habits. Similarly, a streaming platform may identify viewers who enjoy the same types of content.
As a result, companies can create more personalized experiences and make better business decisions. Furthermore, these insights can help improve customer satisfaction and increase revenue.
Reducing Manual Work
Traditionally, labeling millions of records requires significant time and resources. Fortunately, unsupervised learning removes much of this burden by allowing algorithms to explore data independently.
Consequently, organizations can save both time and money while still gaining meaningful insights from their data.
Supporting Data-Driven Decisions
Furthermore, insights discovered through unsupervised learning can help businesses improve marketing strategies, customer experiences, and operational processes.
Because of this, the technology has become an important part of modern analytics. In addition, it helps organizations make decisions based on data rather than assumptions.
How Unsupervised Learning Works?
At first, the technology may seem complex. However, the overall process is relatively straightforward and follows a series of logical steps.
Step 1: Collect Data
First, organizations gather data from various sources.
For example, these sources may include:
- Customer transactions
- Website activity
- Social media interactions
- Sensor readings
- Images and videos
At this stage, the data usually does not contain labels. Nevertheless, it still contains valuable information that can be analyzed.
Read More: AI in Data Science Explained: Everything You Need to Know
Step 2: Prepare the Data
Next, data scientists clean and organize the information before analysis begins.
For example, they may:
- Remove duplicate records
- Fix missing values
- Standardize formats
- Scale numerical data
As a result, the dataset becomes more accurate and easier for algorithms to process. Furthermore, clean data often leads to better results.
Step 3: Apply an Algorithm
After the data has been prepared, an unsupervised learning algorithm begins analyzing it.
Depending on the objective, the algorithm may look for groups, relationships, trends, or hidden structures within the data. Meanwhile, it continues searching for meaningful patterns without relying on predefined labels.

Step 4: Discover Patterns
Once the analysis begins, the model identifies meaningful patterns and relationships.
For example, it may discover customer groups, purchasing trends, unusual behaviors, or common characteristics shared among data points.
As a result, organizations gain valuable insights that would be difficult to find manually.
Step 5: Interpret the Results
Finally, analysts review the findings and determine how they can support business goals.
Although algorithms can identify patterns automatically, human interpretation remains important. Therefore, experts must evaluate the results and decide how to apply the insights in real-world situations.
Key Concepts in Unsupervised Learning
Several important concepts help explain how unsupervised learning works.
Clustering
Clustering is the process of grouping similar data points.
The goal is to place related items into the same group while keeping different items separate.
As a result, businesses can better understand customer behavior and market trends.
Read More: K-Means Clustering Made Easy for Beginners
K-means Clustering
K-means clustering is one of the most widely used clustering methods.
It works by dividing data into a specific number of groups based on similarity.
For example, an online retailer may use K-means clustering for customer segmentation, allowing it to target different customer groups with personalized marketing campaigns.
Hierarchical Clustering
Hierarchical clustering creates a tree-like structure of groups.
Unlike K-means clustering, it shows relationships between clusters at multiple levels.
Therefore, analysts can explore data from a broader or more detailed perspective.
Association
Association techniques identify relationships between items that frequently appear together.
These relationships are known as association rules.
For example, a grocery store might discover that customers who buy coffee often purchase sugar as well.
Consequently, the store can improve product placement and promotional strategies.
Dimensionality Reduction
Many datasets contain hundreds or even thousands of variables.
However, not all variables are equally important.
Dimensionality reduction simplifies large datasets while preserving the most useful information.
Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is one of the most popular dimensionality reduction techniques.
It reduces the number of variables while keeping the most valuable information.
As a result, data becomes easier to analyze and visualize.
Read More: Principal Component Analysis: Learn It the Easy Way
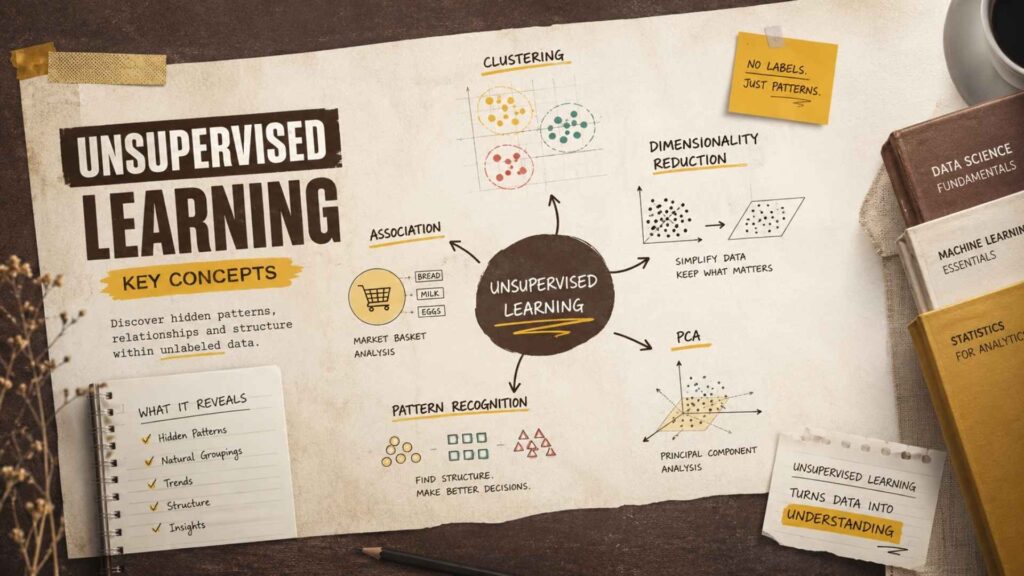
Pattern Recognition
Pattern recognition focuses on identifying recurring trends and structures within data.
Therefore, organizations can better understand behaviors and improve decision-making processes.
Common Unsupervised Learning Algorithms
Different algorithms are designed for different tasks.
| Algorithm Name | Type | Primary Use Case |
|---|---|---|
| K-means Clustering | Clustering | Customer Segmentation |
| Hierarchical Clustering | Clustering | Group Analysis |
| DBSCAN | Clustering | Finding Irregular Groups |
| Principal Component Analysis (PCA) | Dimensionality Reduction | Data Simplification |
| Apriori | Association | Market Basket Analysis |
| Autoencoders | Feature Learning | Data Compression |
| Isolation Forest | Anomaly Detection | Fraud Detection |
Therefore, selecting the right algorithm depends on the specific problem being solved.
Real-World Applications of Unsupervised Learning
Unsupervised learning is used in many everyday technologies.
Google and Content Organization
Google processes enormous amounts of information every day.
To manage this data efficiently, the company uses machine learning techniques to organize search results and categorize news content.
As a result, users receive more relevant information.
Netflix and Customer Segmentation
Netflix studies viewing habits to understand audience preferences.
By identifying groups of users with similar interests, the platform can recommend content more effectively.
Consequently, viewers discover movies and shows they are more likely to enjoy.
Amazon and Product Recommendations
Amazon analyzes purchasing behavior to uncover relationships between products.
For example, customers who buy one product may frequently purchase another related item.
Therefore, Amazon can generate useful product recommendations.
Read More: What’s Amazon
Meta and Community Detection
Meta manages billions of social connections.
Using unsupervised learning, the company can identify communities, groups, and relationships within its social networks.
As a result, content can be delivered more effectively to users.
Tesla and Sensor Data Analysis
Tesla vehicles generate massive amounts of sensor data.
Unsupervised learning helps identify unusual patterns and supports anomaly detection.
Consequently, potential issues can be identified before they become serious problems.
Healthcare
Healthcare organizations use unsupervised learning to group patients with similar characteristics.
As a result, researchers can uncover valuable medical insights and improve treatment strategies.

Cybersecurity
Cybersecurity systems use anomaly detection to identify suspicious activity.
Since new threats appear regularly, these systems must recognize unusual behavior even when it has never been seen before.
Therefore, unsupervised learning plays an important role in modern security solutions.
Read More: Computer security
Benefits of Unsupervised Learning
Many organizations use unsupervised learning because it offers several important advantages.
Works Without Labels
First, it can analyze data without requiring labeled examples.
As a result, organizations can begin exploring information immediately.
Finds Hidden Insights
Additionally, it can uncover patterns that humans might miss.
Therefore, businesses gain valuable insights from their data.
Handles Large Datasets
Modern organizations often manage enormous amounts of information.
Fortunately, unsupervised learning can process large datasets efficiently.
Supports Better Decisions
Furthermore, discovered patterns often lead to smarter business decisions and improved customer experiences.
Improves Data Understanding
Finally, it helps analysts better understand complex data structures and relationships.
Limitations of Unsupervised Learning
Despite its advantages, unsupervised learning also has several challenges.
Results Can Be Difficult to Evaluate
Since there are no predefined answers, measuring success can be difficult.
Therefore, evaluation often depends on human judgment
High Computational Costs
Large datasets may require significant processing power.
Consequently, analysis can become expensive.
Sensitive to Data Quality
Poor-quality data can produce misleading results.
For this reason, careful data preparation is essential.
Interpretation Challenges
Sometimes algorithms identify patterns that are difficult to explain.
As a result, expert analysis is often required.
Benefits vs. Limitations
| Benefits | Limitations |
|---|---|
| Works with unlabeled data | Results may be subjective |
| Finds hidden patterns | Evaluation can be difficult |
| Scales to large datasets | Requires computing resources |
| Supports customer segmentation | Sensitive to poor-quality data |
| Enables anomaly detection | Insights may be difficult to interpret |
Common Mistakes to Avoid
Many beginners make similar mistakes when working with unsupervised learning.

Choosing the Wrong Algorithm
Not every algorithm is suitable for every task.
Therefore, understanding the strengths and weaknesses of each method is important.
Ignoring Data Cleaning
Dirty data often produces poor results.
Consequently, data preparation should never be overlooked.
Assuming Every Pattern Is Useful
Just because an algorithm finds a pattern does not mean it has business value.
Therefore, results should always be validated.
Using Too Many Features
Including unnecessary variables can reduce performance.
As a result, dimensionality reduction techniques such as PCA are often helpful.
Best Practices for Success
Organizations can improve results by following several best practices.
Define Clear Goals
Before starting a project, establish clear objectives.
This ensures the analysis remains focused.
Focus on Data Quality
Clean and accurate data leads to better outcomes.
Therefore, invest time in preparation.
Test Multiple Algorithms
Different algorithms may reveal different insights.
Consequently, experimentation often produces better results.
Use Visualizations
Visual tools help analysts understand clusters and patterns more easily.
Furthermore, they improve communication with stakeholders.
Validate Findings
Finally, compare discovered patterns with real-world behavior to ensure the insights are meaningful.
Read More: Supervised Learning: A Practical Tutorial
Future Trends in Unsupervised Learning
The future of unsupervised learning is very promising.
More Self-Supervised Learning
Researchers are developing methods that combine the strengths of supervised and unsupervised learning.
As a result, models can learn from larger datasets with fewer labels.
Better Deep Learning Models
Advanced deep learning systems continue to improve pattern discovery capabilities.
Therefore, more complex data can be analyzed effectively.
Improved Anomaly Detection
Future systems will become even better at identifying unusual events and behaviors.
Consequently, industries such as finance, healthcare, and cybersecurity will benefit significantly.
Real-Time Data Analysis
As computing power grows, algorithms will process information faster.
As a result, businesses will gain insights almost instantly.
Conclusion
Unsupervised Learning is a powerful machine learning approach that helps organizations discover hidden patterns, relationships, and structures within unlabeled datasets.
Through techniques such as clustering, association analysis, dimensionality reduction, Principal Component Analysis (PCA), customer segmentation, and anomaly detection, businesses can gain valuable insights from their data.
Moreover, leading companies such as Google, Netflix, Amazon, Meta, and Tesla already use these methods to improve services, understand users, and make better decisions. Although challenges exist, the benefits often make unsupervised learning an essential part of modern data science and artificial intelligence.
Read More: Text-to-Speech: A Complete Guide for Better Digital Content
Frequently Asked Questions (FAQs)
What is Unsupervised Learning?
It is a machine learning method that finds patterns and relationships in unlabeled data.
What is the main purpose of unsupervised learning?
Its main goal is to discover hidden patterns and structures within data.
What is clustering?
Clustering is the process of grouping similar data points together.
What is K-means clustering?
K-means clustering is a popular algorithm used to divide data into similar groups.
What is PCA?
Principal Component Analysis (PCA) is a technique used to reduce the number of variables in a dataset while preserving important information.
What is anomaly detection?
Anomaly detection identifies unusual data points or behaviors that differ from normal patterns.
Does unsupervised learning require labeled data?
No. It works with unlabeled datasets.
Where is unsupervised learning used?
It is used in marketing, healthcare, finance, cybersecurity, social media, and recommendation systems.
Is unsupervised learning important?
Yes. It helps organizations uncover valuable insights that may not be visible through manual analysis.

Call To Action
Need SEO content that ranks on Google and keeps readers engaged?
I create:
- SEO blog posts
- Keyword-focused articles
- Human-style content
- Easy-to-read blogs
- High-engagement website content
Let’s build content that performs.
📧 Email: craziya167@gmail.com
Author Bio:
Digital Raziya is an SEO content writer who specializes in AI, technology, and digital marketing topics. Her goal is to create clear, engaging, and easy-to-understand content for online readers.











Post Comment
You must be logged in to post a comment.