Data Augmentation Made Simple for Beginners

Today, data and data augmentation is the fuel of technology.
However, data is not always enough.
Because of this, models sometimes fail.
That is where data augmentation becomes powerful.
In simple words, it increases training data.
At the same time, it keeps meaning intact.
Artificial Intelligence depends heavily on data.
Therefore, more quality data improves performance.
As a result, models become smarter.
In this guide, everything is explained clearly.
Moreover, concepts stay simple and practical.
Most importantly, beginners can understand easily.
Let us begin step by step.
What Is Data Augmentation?
Data augmentation is a technique.
It creates new data from existing data.
However, it does not collect new samples.
Instead, it modifies current data slightly.
For example, images can be rotated.
Text can be rephrased.
Because of this, dataset size increases.
Meanwhile, original meaning stays similar.
Therefore, learning improves.
In short, data augmentation strengthens training data.
Why It Is Important ?

Machine learning models need large datasets.
However, collecting data is expensive.
Sometimes, data is limited.
Therefore, models overfit easily.
Overfitting means poor real-world performance.
This is a common problem.
Luckily, data augmentation solves this issue.
It creates variety inside the dataset.
Consequently, models generalize better.
In addition, accuracy often improves.
At the same time, robustness increases.
Hence, augmentation is essential.
Connection Between Data Augmentation and AI
Artificial Intelligence systems learn patterns.
However, limited data restricts learning.
Therefore, AI performance suffers.
With data augmentation, variety increases.
Because of this, AI sees more examples.
As a result, pattern recognition improves.
Interestingly, it include PCA and AI techniques.
PCA can reduce noise before augmentation.
AI can generate synthetic samples.
Together, these methods boost intelligence.
Moreover, training becomes more stable.
That combination is powerful.
A Short History of Supervised Learning
Supervised learning came first.
Initially, models required labeled data.
Humans provided correct answers.
Over time, datasets grew larger.
Because of this, labeling became costly.
Accuracy demands also increased.
Soon, researchers faced challenges.
Models overfitted small datasets.
Performance dropped outside training data.
Then, augmentation techniques emerged.
They expanded datasets without new collection.
This changed machine learning practice.
Read more: Master AI Data Mining to Unlock Hidden Insights
Evolution of Learning Methods
| Era | Method | Key Focus |
|---|---|---|
| 1950s | Rule-based systems | Fixed logic |
| 1980s | Supervised learning | Labeled prediction |
| 1990s | Statistical ML | Feature engineering |
| 2000s | Data augmentation | Dataset expansion |
| 2010s | AI + Deep Learning | Automatic pattern learning |
This evolution explains why augmentation matters today.
How Data Augmentation Works
The idea is simple.
First, take original data.
Then, apply small transformations.
For images, flip horizontally.
For audio, add slight noise.
For text, replace words carefully.
Because of these variations, new samples appear.
Still, the label remains the same.
Therefore, learning strengthens.
Importantly, quality must remain high.
Otherwise, models learn wrong patterns.
So balance is necessary.
Types of Data Augmentation

Different data types need different methods.
Therefore, techniques vary widely.
Image Augmentation
Images can be rotated.
Brightness can be adjusted.
Zoom can be applied.
These changes create diversity.
Meanwhile, object identity remains stable.
Thus, image models improve.
Text Augmentation
Text data also needs variety.
Synonyms can replace words.
Sentences can be slightly reordered.
However, meaning must stay correct.
Otherwise, models get confused.
Careful editing is important.
Audio Augmentation
Audio signals can be shifted.
Noise can be added softly.
Speed can change slightly.
These variations simulate real conditions.
As a result, speech models perform better.
Robustness increases naturally.
Data Augmentation Include PCA and AI

Many beginners think augmentation only modifies data.
However, modern approaches go further.
Advanced systems combine techniques.
For example, PCA reduces feature dimensions.
Because of this, noise decreases.
Then, augmentation becomes more effective.
Similarly, AI models generate synthetic samples.
Generative models create realistic data.
This expands datasets dramatically.
Therefore, data augmentation include PCA and AI methods.
Together, they form a smart pipeline.
This is the future of model training.
Benefits of Data Augmentation
First, overfitting reduces significantly.
Second, model accuracy improves.
Third, training becomes more stable.
In addition, datasets become balanced.
Rare classes gain more examples.
Consequently, fairness improves.
Moreover, real-world performance strengthens.
Models handle unexpected situations better.
Confidence increases overall.
Limitations You Should Know
Despite its power, augmentation has limits.
Too much transformation harms data.
Meaning can shift accidentally.
Also, low-quality synthetic data misleads models.
Therefore, testing is necessary.
Evaluation should always follow.
Balanced use brings best results.
Blind usage creates problems.
Awareness prevents mistakes.
Eye-Catching Insight: Think of Augmentation as Smart Practice
Imagine preparing for an exam.
You solve similar questions repeatedly.
Patterns become clearer each time.
Data augmentation works the same way.
Models practice with variations.
Learning becomes deeper.
This simple analogy makes the idea memorable.
Understanding feels easier instantly.
That clarity matters.
When Should You Use Data Augmentation?
Use augmentation when data is limited.
Apply it when models overfit.
Consider it when accuracy drops.
However, avoid it with massive datasets.
Sometimes, extra changes are unnecessary.
Decision depends on context.
Smart evaluation always helps.
Testing reveals true impact.
Evidence should guide action.
Read more: Data Visualization Made Simple: Beginner’s Guide
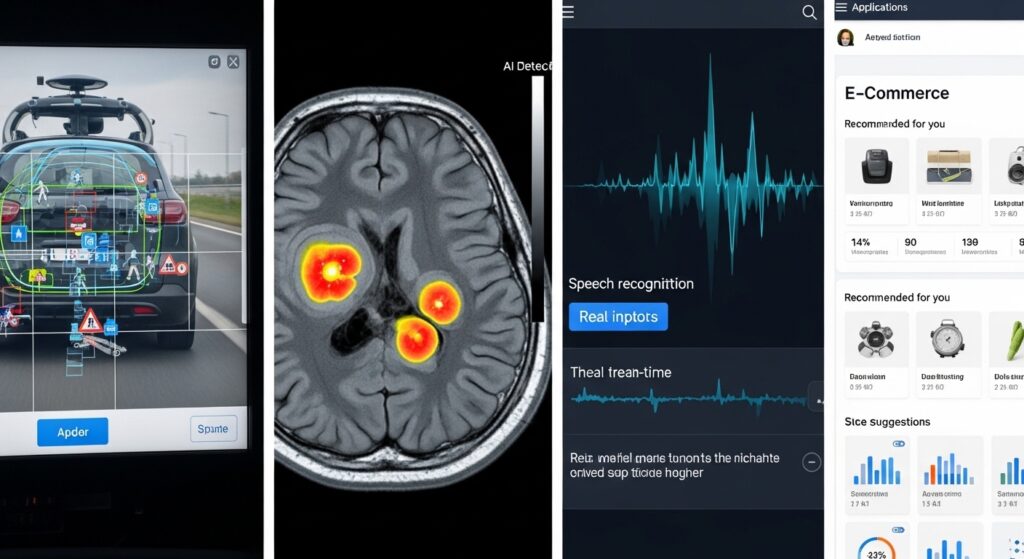
Data Augmentation in Real-World AI
Self-driving cars use augmented images.
Medical systems analyze augmented scans.
E-commerce uses augmented customer data.
Facial recognition improves through variations.
Speech assistants train with noisy audio.
Recommendation systems benefit too.
Clearly, augmentation powers modern AI.
Its impact is widespread.
Innovation continues growing.
Best Practices for Beginners
Start with small transformations.
Evaluate performance carefully.
Monitor validation accuracy closely.
Next, increase variation gradually.
Avoid extreme modifications.
Always preserve original meaning.
Finally, compare results before and after.
Measure improvement clearly.
Data should support decisions.
Common Beginner Mistakes
Many beginners apply too many changes.
Others forget validation checks.
Some ignore class balance.
These mistakes reduce performance.
Fortunately, they are easy to fix.
Learning from errors is important.
Experience builds better judgment.
Practice improves understanding.
Confidence grows naturally.
The Future of Data Augmentation
AI-generated data is rising fast.
Generative models create realistic samples.
Deep learning drives innovation.
Soon, automated pipelines will dominate.
Smart systems will choose best transformations.
Efficiency will increase further.
Therefore, learning augmentation now is wise.
Future AI depends on it.
Preparation brings advantage.
FAQs About Data Augmentation
What is data augmentation in simple terms?
Data augmentation creates new training data.
It modifies existing samples slightly.
Why is data augmentation important?
It reduces overfitting.
It improves model accuracy.
Does data augmentation include PCA and AI?
Yes, modern methods combine them.
They enhance performance together.
Is data augmentation only for images?
No, it works for text and audio too.
Different data types use different methods.
Can too much augmentation be harmful?
Yes, excessive changes distort meaning.
Balanced use is important.
Final Thoughts
Data is powerful.
However, more smart data is better.
That is why data augmentation matters.
It strengthens learning systems.
It improves AI reliability.
It supports innovation.
Now, you understand the concept clearly.
More importantly, you see its importance.
This knowledge builds a strong foundation.
Call To Action:
Want SEO-optimized content that ranks higher and attracts the right audience?
I help websites grow with keyword-focused, easy-to-read blog posts and strong on-page SEO strategies.
Get in touch today and let’s grow your content the smart way.
📧 Email: craziya167@gmail.com
📞 Phone / WhatsApp: +92 03110115488












Post Comment
You must be logged in to post a comment.