Ultimate Guide to K-Means Clustering Made Simple

Introduction
Data is everywhere today; indeed, it is generated in huge amounts every second.
in fact, (K-Means Clustering). However, raw data is often messy.
So, we need a way to organize it.
That is where k-means clustering helps.
It is a simple method; in fact, it is easy to understand.
Moreover, it groups similar data together.
In this article, you will learn what it is and how it works; therefore, you will better understand its importance.
You will also see real-life examples.
Read More: Clustering in AI and Machine Learning: Everything You Need to Know
What Is K-Means Clustering?
K-means clustering turns complex data into clear and meaningful groups
K-means clustering is a way to divide data into groups; in other words, it organizes data into meaningful clusters. in other words, it organizes data into meaningful categories.
Furthermore, each group is called a cluster.
The letter K means the number of groups.
For example, if K is 3, the data will be divided into 3 clusters.
Each cluster contains similar items.
On the other hand, items in different clusters are not very similar.
Because of this, it helps us understand patterns easily.
Here are the key points to understand K-means clustering; therefore, it helps in building a clear understanding of the method.
- K-means is a popular unsupervised machine learning algorithm; indeed, it is widely used in data analysis.
- In addition, it groups data based on similarity.
- Meanwhile, the value of K defines the number of clusters.
Read More: Understanding Ai Monitization: Make Money Artificial Intelligence
| Concept | Explanation |
|---|---|
| K-Means Clustering | A method used to divide data into meaningful groups (clusters) |
| Cluster | A group of similar data items |
| K (Number of Clusters) | Defines how many groups the data will be divided into |
| Similarity | Data points in the same cluster share similar characteristics |
| Difference | Data in different clusters are not very similar |
| Type of Algorithm | Unsupervised Machine Learning Algorithm |
| Main Purpose | To find patterns and organize complex data into simple groups |
| Use in AI | Widely used in data analysis, machine learning, and pattern recognition |
Why Is K-Means Clustering Important?
Many businesses use data every day.
But data alone does not give meaning.
Therefore, grouping data makes it useful.
For example, companies group customers based on buying habits.
As a result, they can send better offers.
Similarly, schools can group students by performance.
This helps teachers give better support; as a result, students receive more effective guidance.
Read More: Google Colab: The Ultimate Guide for Beginners (2026)
How Does K-Means Clustering Work?
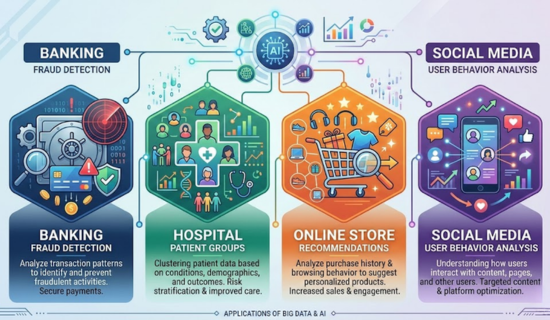
The process is simple; in fact, it follows clear steps.
Firstly, choose the number of clusters (K).
Next, the system picks random center points.
After that, each data point joins the nearest center.
Then, the center moves to the middle of its group.
This process repeats again and again.
Finally, the groups stop changing.
At this stage, the clusters are ready.
Read More: PyTorch Basics to Advanced: A Complete Learning Guide 2026
Real Life Example
Imagine a shoe store; for example, the owner wants to understand customers.
In particular, some customers buy sports shoes.
On the other hand, others prefer formal shoes.
Instead of checking each person one by one,
the owner uses k-means clustering.
As a result, customers are grouped by buying style.
Now marketing becomes easier.
Read More: Coursera: Complete Guide to Online Courses and Degrees

Advantages of K-Means Clustering
There are many benefits; for instance, it helps in better understanding of data.
First, it is easy to understand.
Second, it works fast on large data.
In addition, it saves time.
Most importantly, it shows clear patterns.
Because of this, beginners like to learn it first.
Read More: Coursera: Complete Guide to Online Courses and Degrees
Limitations of K-Means Clustering
However, it also has limits.
You must choose the right number of clusters; otherwise, the results may not be accurate.
If so, choosing the wrong number can lead to poor results.
Also, it works best with clear and clean data.
Messy data can reduce accuracy.
Even so, it is still very popular.
Read More: Text-to-Speech:A simple and Complete AI Voice Guide for 2026
| Aspect | Details |
|---|---|
| Advantages | Fast, simple, easy to use |
| Limitations | Needs correct K value |
| Data Requirement | Works best with clean data |
| Usage | Pattern recognition |
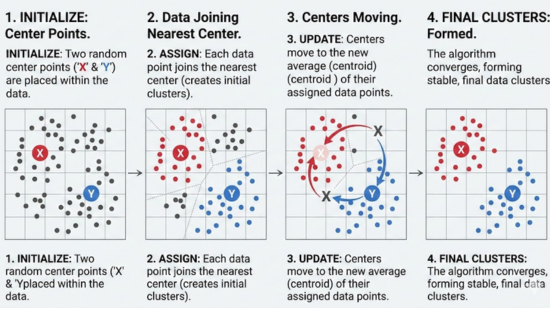
Where Is K-Means Clustering Used?
It is used in many fields.
For example, banks use it to detect fraud.
Hospitals use it to study patient groups.
Online stores use it for product suggestions; for example, this improves customer recommendations.
Similarly, social media platforms use it to study user behavior.
Because of its simplicity, it is widely used.
Bullet Points
- Used in fraud detection systems
- Helps analyze patient groups in healthcare
- Improves product recommendation systems
- Studies user behavior on social platforms
- Widely used due to simplicity and efficiency
Read More: Discover the Best AI Models You Should Know in 2026
Final Thoughts
K-means clustering is simple yet powerful; however, it is highly effective in practice.
In addition, it helps us group similar data.
Although it has some limits,
it remains one of the best starting methods in data science.
If you want to understand data better,
Learning this method is a great first step
Read More: Discover People Fast with Powerful Face Recognition Tool
Bullet points
- Strong foundation for advanced learning
- Simple yet powerful algorithm
- Helps group similar data easily
- Great for beginners in data science
- Widely used in real-world applications
K-means clustering proves that even simple algorithms can unlock powerful insights.
FAQs About K-Means Clustering
1. What is k-means clustering?
K-means clustering is a way to group data; in simple terms, it organizes information into clusters; therefore, making patterns easier to understand.
In particular, it puts similar items together.
2. What does the letter K mean?
K shows the number of groups.
For example, if K is 4, there will be 4 clusters.
3. Why is k-means clustering used?
It helps organize messy data.
As a result, patterns become clear.
4. Is k-means clustering hard to learn?
No, it is simple.
In fact, beginners can understand it easily.
5. How do we choose the value of K?
You test different numbers.
Then, you pick the one that gives better results.
6. Does k-means clustering work with big data?
Yes, it works well with large data.
Therefore, many companies use it.
Read More: Ultimate Guide to K-Means Clustering with Python Example
7. What type of data is best for k-means?
It works best with number data.
However, clean data gives better results.
8. Can k-means give wrong results?
Yes, sometimes it can.
For example, a wrong K value may cause problems.
9. How many steps are in k-means?
There are a few simple steps.
First, choose K.
Then, group the data.
Finally, repeat until it stops changing.
10. Where is k-means clustering used?
It is used in business, health, and marketing.
In addition, it is common in data science.
11. Is k-means clustering fast?
Yes, it is usually fast.
Because of this, it saves time.
12. Can it find hidden patterns?
Yes, it can show patterns.
As a result, decisions become easier.
13. What is a cluster?
A cluster is a group of similar items; in fact, each cluster represents a specific pattern in the data.
Moreover, each cluster has a center point.
14. Is k-means used in real life?
Yes, it is used every day.
For example, online stores use it for customer groups.
Read More: Ultimate Guide to K-Means Clustering Made Simple
15. Should beginners learn k-means first?
Yes, they should.
Because it is simple and useful.
Call to action
Want to get higher ranking, bring more visitors, and grow your business online?
We can help you improve your website with professional SEO services that give real results.
Our service:
On-Page SEO
Technical SEO
Keyword Research
Site Audit
📩 Get in Touch Today
- Email: zarirahc@gmail.com
- WhatsApp: +92 0311 0115488
- Website: https://minsaai.com/
Author bio:
Zarirah Asif is a creative content writer who loves turning ideas into engaging words. She writes SEO-friendly articles that are easy to read and useful for readers. Her goal is to help brands stand out with quality content. She is always learning and improving her writing skills











Post Comment
You must be logged in to post a comment.