Model training: Powerful Guide to AI Growth in 2026
Model training is the process of teaching an AI system with data, examples, and feedback. As a result, it helps a model learn patterns and answer with better skill. Today, this work affects search, health, finance, apps, and customer support. It also shapes how brands use AI safely. A useful model needs more than size. It needs clean inputs, clear goals, strong tests, and careful review. This guide explains fresh key trends. It also shows what teams should watch in 2026.
This article explains how model training teaches AI systems using data, examples, and feedback to improve their performance. First, it shows how AI is now used in real-world areas like search, healthcare, finance, and customer support. In addition, the focus is shifting from large models to clean data, clear goals, and strong testing. Moreover, new trends like synthetic data, reward learning, and privacy are shaping AI in 2026.
Read More: Ultimate Guide to K-Means Clustering with Python Example
Why Model training matters
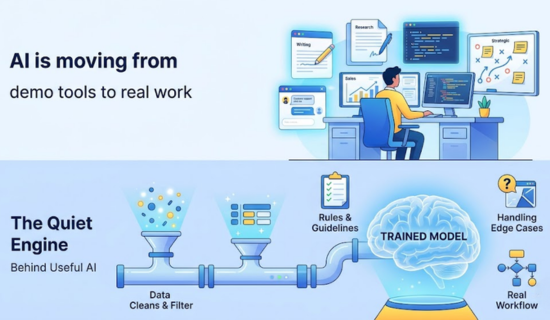
AI is moving from demo tools to real work. For example, teams now use it for writing, coding, support, research, sales, and planning. As a result, that growth creates a new demand. Models must be useful, safe, and easy to control.
A model can sound smart and still be wrong. Model training can miss brand tone. It can repeat private details. It can learn weak patterns from poor data. Training helps reduce these problems.
“Clean data is the quiet engine behind useful AI.”
Good training gives teams more control. It helps a model follow rules, handle edge cases, and fit a real workflow. It also helps leaders measure value before spending more money.
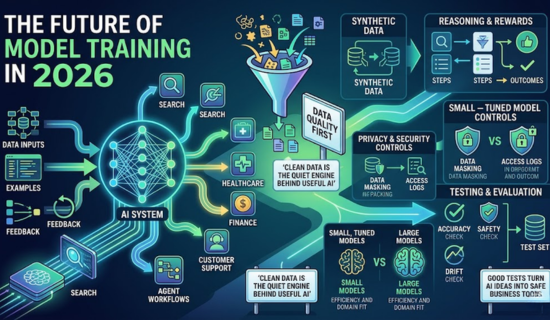
What changed in 2026 in Model training
The AI market is no longer chasing size alone. Bigger models still matter, yet they are not enough. Data quality, privacy, cost, and testing now shape results.
Synthetic data is getting more attention. It can create examples when real data is rare. This is useful in health, law, finance, and robotics. Still, weak synthetic data can spread bias. Teams must test it like real data.
Reasoning is another major trend. New methods reward correct steps, not only nice answers. This helps models solve math, code, and structured tasks. It also supports agent systems that use tools.
Read More: TensorFlow vs PyTorch: Which Is Better for Beginners?
| Training trend | What changed | Smart business action |
|---|---|---|
| Synthetic data | More teams use created examples | Check quality before scaling |
| Reasoning rewards | Models learn from scored results | Build clear grading rules |
| Privacy controls | Users expect data limits | Set opt-in rules early |
| Smaller models | Lean models can work well | Tune for one task first |
| Agent workflows | Tool actions create signals | Track steps and outcomes |
Data quality comes first
Model training needs data that is clean, useful, and legal. Poor data can make a model slow, biased, or unsafe. Clean data helps the system learn the right patterns.
Start by removing duplicate files. Delete outdated facts. Remove private details when they are not needed. Keep source notes for each data group. This helps teams audit the process later.
Labels also matter. A label tells the model what a good answer looks like. However, if labels are rushed, the model learns confusion. In fact, a small set of strong labels can beat a large weak set.
“A small model with trusted data can beat a large model with weak data.”
Data teams should review samples by hand. They should score tone, accuracy, safety, and usefulness. These checks save money during later training rounds.
The main training methods
Different goals need different methods. For instance, a support bot does not need the same setup as a medical tool. Similarly, a coding assistant needs strong tests. Meanwhile, a brand writer needs voice control.
| Method | Best for | Main risk |
|---|---|---|
| Pre-training | Broad language skill | High cost |
| Fine-tuning | Brand style and tasks | Overfitting |
| Reward training | Better reasoning | Bad reward rules |
| Distillation | Smaller fast tools | Rights issues |
| Evaluation sets | Quality checks | Narrow test cases |
Fine-tuning is popular for business use. Specifically, it adapts a base model to a narrow task. As a result, this can improve tone, format, and domain fit.
Reward training is useful for hard tasks. It teaches the model through scored results. A grader checks if the answer meets a goal. The model then learns from that signal.
Distillation makes smaller models learn from stronger models. It can lower cost and speed up apps. Yet teams must respect licenses and data rights.
Read More: Computer Vision in AI: A Complete Beginner-Friendly Guide
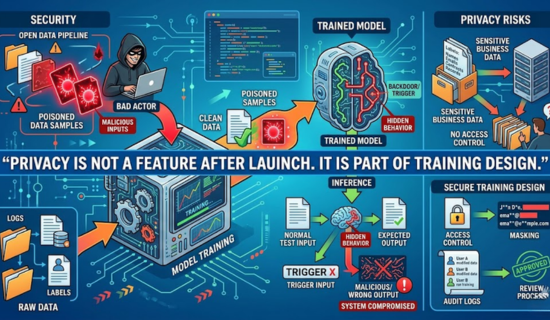
Security and privacy risks
Model training can fail when data pipelines are open and unchecked. Bad actors may insert harmful samples. These samples can create hidden behavior. This is called data poisoning.
Poisoned data can make a model act strangely after a trigger. At first, the model may look normal in most tests. Therefore, that makes the risk hard to spot.
Privacy is another issue. Business data may include names, emails, records, or contracts. Teams should avoid training on sensitive data without permission. They should use masking when possible.
“Privacy is not a feature after launch. It is part of training design.”
Access control is also needed. Only approved staff should handle training data. Logs should show who changed files. Review steps should be written and stored.
Read More:Ultimate Guide to K-Means Clustering with Python Example
Cost and compute choices in Model training
Model training costs can rise fast. For example, large runs need chips, power, storage, and expert time. As a result, many teams cannot afford endless experiments. Therefore, they need a focused plan.
Start with a small task. Use a strong baseline model. Build a test set from real user needs. Improve the data before adding more compute.
A small tuned model may serve a business better. In many cases, it can be faster and cheaper. Additionally, it may also be easier to host. As a result, this matters for support, search, and internal tools.
Leaders should track cost per useful answer. They should also track user time saved. These numbers show if training creates real value.
Read More: ChatGPT AI: Everything you need to know about the ChatGPT AI
Testing makes AI safer
Model training also needs strong testing. Tests should cover easy cases, hard cases, and strange cases. They should include unsafe requests and private data traps.
A good test set stays separate from training data. As a result, this protects the score from being fake. However, if the model sees the test early, the score loses value.
Human review still matters. Experts can find tone issues, legal risks, and unclear answers. Users can report weak results after launch. These reports should improve the next data set.
“Good tests turn AI ideas into safe business tools.”
Testing should not stop after release. Models can drift when products change. Data can age. User needs can shift. A regular review keeps the system useful.
Best steps for small teams in Model training
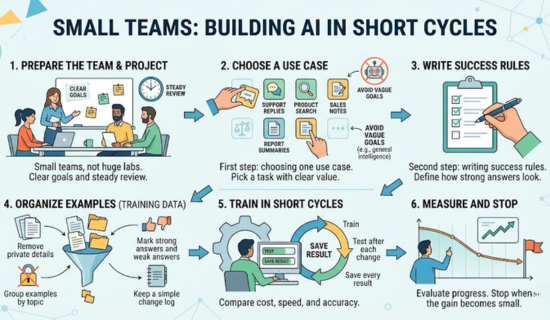
First, Small teams do not need huge labs.
Next, they need clear goals and steady review.
Then, The first step is choosing one use case.
After that, The second step is writing success rules.
For example, Pick a task with clear value.
However, Good examples include support replies, product search, sales notes, and report summaries.
Avoid vague goals like general intelligence:
- First, Remove private details.
- Next, Group examples by topic.
- Then, Mark strong answers and weak answers.
- Finally, Keep a simple change log.
Train in short cycles. Test after each change. Save every result. Compare cost, speed, and accuracy. Stop when the gain becomes small.
Read More: Decision Trees: A Complete Guide with Examples & Best Steps
Common mistakes to avoid in Model training
Many teams train too early. People have no test set. They have no data policy. They have no clear owner. This creates waste.
Another mistake is using more data without checking it. More data can add noise. Better data often helps more than bigger data.
Some teams ignore user feedback. That is risky. Real users find issues that lab tests miss. Their feedback can improve prompts, tools, and training sets.
A final mistake is hiding limits. Every model has weak areas. Teams should document those limits. Clear notes help users trust the system.
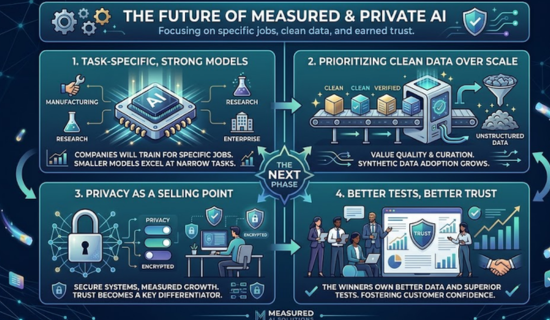
Future outlook of Model training
The next phase will focus on useful, private, and measured AI. In particular, companies will train models for specific jobs. As a result, they will value clean data over random scale.
Additionally, more tools will support reward-based learning. At the same time, more teams will use synthetic data. Meanwhile, smaller models will become stronger for narrow tasks. Ultimately, privacy will become a selling point.
AI training will keep changing as products grow. The winners will not only own large systems. They will own better data, better tests, and better trust.
Read More: Text-to-Speech:A simple and Complete AI Voice Guide for 2026
10 FAQs
Q: What is Model training?
To begin with, it is the process of teaching an AI system using data and feedback. As a result, the system learns patterns and improves its performance over time.
Q: Why does AI need training?
In general, training helps AI learn patterns, tasks, tone, and safe behavior. As a result, it becomes more accurate, useful, and reliable in different real-world situations.
Q: What data is best for AI?
First of all, clean, legal, fresh, and task-specific data works best for training AI systems. In other words, the quality of the data directly affects the quality of the model’s learning. Moreover, when data is well-organized and relevant to the task, the model can understand patterns more clearly and produce more accurate results. As a result, better data leads to better performance, fewer errors, and more reliable outputs in real-world use.
Q: Is synthetic data useful?
Yes, but it needs strong checks before use.
Q: What is fine-tuning?
In general, fine-tuning adapts a base model for a narrow task. As a result, it becomes more accurate and better suited to specific use cases.
Read More: PyTorch Basics to Advanced: A Complete Learning Guide 2026
Q: What is reward training?
In simple terms, it teaches a model through scores from a grader. As a result, the model learns which outputs are better and gradually improves its performance.
Q: Can training data be dangerous?
Yes, if it includes private, biased, or poisoned content, then it can harm the model’s behavior and lead to unsafe or unreliable results.
Q: Do small businesses need custom training?
Some do, but many can start with better prompts and tests.
Q: How can teams lower costs?
To begin with, they can start small, test often, and improve data first. In this way, they reduce risks and gradually build better-performing models.
Q: What should team measure?
They should measure accuracy, safety, speed, cost, and user value.
Read More: Ultimate Guide to K-Means Clustering Made Simple
Call To Action
Need clear and SEO-friendly tech content for your brand? I can help with:
- Tech Article Writing
- On page SEO
- Keyword Research & Optimization
- Site Audit
Contact me today:
Email: writerzarirah@gmail.com
What’s App: +92 371 4778412
Author Bio
Zarirah Asif is a creative content writer who loves turning ideas into engaging words. She writes SEO-friendly articles that are easy to read and useful for readers. Her goal is to help brands stand out with quality content. She is always learning and improving her writing skills.












Post Comment
You must be logged in to post a comment.